>
>http://sheepman.sakura.ne.jp/diary/?date=20060817#p01
> を見て「へー」と思ったが、「日本語は英語みたいに単語で区切ることができないので……」と書いてあったので、んじゃあ mecab で、ということでやってみた。
>
>対象は自分の日記。日記で、たぶん扱いやすいデータは HTML 様のデータになっているのでこれを使う。すると、英数字のみの未知語は HTML タグなどである可能性があるので、そういうのは省いた。あと句読点などの記号類も省いた。もちろん、行末端も省いた。そういった諸々の結果が次のとおり。
>
>
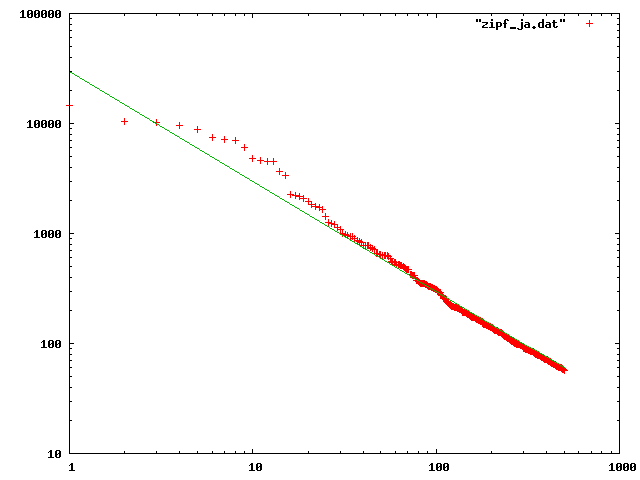
>
>緑のラインは、位置合わせのために 30000/x としている。ようするに傾き-1 のラインで、良く一致しているという感じのような気がする。ただまぁ、テストのために mecab の結果を眺めていたら、ひらがなが連続するような場所ではまとめて1つの単語にせずにたくさんの助詞としているケースがあったので、そういった性能も関係しているのかもしれない。
>
>ちなみに抽出コードはこんな感じ。
>
>$KCODE = 'e'
require 'pathname'
words = {}
Pathname.new("/path/to/my/blog/files/").find do |f|
if /\.html$/ =~ f then
result = `mecab #{f.to_s}`
result.gsub!(/^(。|、|』|」)?[\x21-\x7e]+\s+未知語.*$/, "")
result.gsub!(/^.*記号.*$/, "")
result.gsub!(/^EOS$/, "")
result.split(/\n+/).each do |l|
word = l.split[0]
if word then
words[word] ||= 0
words[word] += 1
end
end
$stderr.puts f
end
end
words.to_a.sort{|a,b| b[1] <=> a[1]}[0..500].each_with_index{|v, i| puts "#{i+1} #{v[1]}"}
>
>んでこの出力結果を gnuplot で、 set logscale xy してプロットしました。
>
>追記: あんまり誰もツッコミを入れてくれない気がするので自分で書くけど、こういうのって mecab の採用しているアルゴリズムの影響も受けるよねぇ。上にもちょろっと書いたけど、ある文字列からどう単語を抽出するか、という背後には何らかのモデルがあるはずで、そのモデルの想定を測っているだけ、ということもあるだろうと。その辺どうなんですか、という気は、もちろんします。あんま詳しくないんでよくわからないんですが。
>
